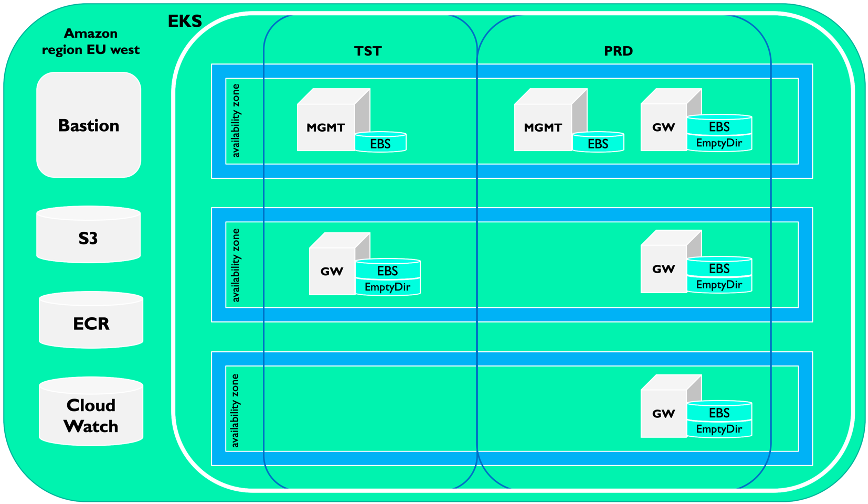
A cost-efficient setup of IBM API Connect (APIC) has been deployed to Amazon EKS. To achieve this, per environment, a single instance of the API Manager, Developer Portal and Analytics subsystem is deployed to a ‘mgmt’ worker node. In the production environment three replicas of the API Gateway are deployed, one gateway per availability zone. Business can also look at a identity and access management solution like HelloID to easily manage your organization and mitigate any security threats.
Having single instances of the mgmt nodes and a single instance of the gateway node in the test environment lowers the cost, with the downside that the subsystems on these nodes are not highly available.
A single (managed) kubernetes cluster is used to host a production and a test environment; separate namespaces are used for the test and production environments: ‘tst-apic’ for the test environment and ‘apic’ for the production environment.
Architecture
Used storage types:
| Component | Role |
| Bastion | Hosts the IBM installation images, entry point to the cluster during installation |
| S3 storage | Storage for backup of the API Manager, Developer Portal and Analytics subsystems |
| ECR | Registry for hosting the docker images of APIC |
| EBS | Block storage as required by APIC |
| CloudWatch | Used to store the logs |
| EmptyDir | Kubernetes type of storage which is used by the gateways (the gateways also use EBS) |
In addition, in front of APIC there is a NetScaler with FortiGate firewalls around it followed by an Amazon load balancer.
IBM API Connect license
The license the customer has purchased was IBM API Connect Enterprise Tier Hybrid Million. This hybrid entitlement allows for deployment to any cloud and/or on-premise location using an unrestricted selection of hardware. The components can be managed using a single web interface.
For this license customers need to count API call on a periodic basis; a script for this can be found at: https://www.ibm.com/support/knowledgecenter/SSMNED_2018/com.ibm.apic.cmc.doc/tapic_analy_script_count_api_calls.html.
Versions
| Component | Version |
| IBM API Connect | 2018.4.1.9-ifix1.0 |
| EKS/Docker | 18.06.1-ce |
| EKS/Kubernetes | 1.14 |
| Helm | 2.16.1 |
Cluster sizing
| Environment | K8s namespace | # | Node name | Node type | Local storage on / [GB] | vCPU | Memory [GB] |
| TST | tst-apic | 1 | mgmt | m5.4xlarge | 200 | 16 | 64 |
| TST | tst-apic | 1 | gw | t3.xlarge | 100 | 4 | 16 |
| PRD | apic | 1 | mgmt | m5.4xlarge | 200 | 16 | 64 |
| PRD | apic | 3 | gw | t3.xlarge | 100 | 4 | 16 |
Bastion
The bastion is the entry point the cluster when installing the components.
| Environment | Local storage on / [GB] | vCPU | Memory [GB] |
| Bastion | 50 on /32 on /data | 2 | 2 |
In reality 3 to 4 vCPU are available to the gateways, some CPU is used by the NGINX-ingress controller and the FluentD agent.
The reason for having the local storage is that the OS needs storage and the /var/lib/docker/overlay2 consumes a lot of space, currently after a fresh install around 23 GB. EBS storage will be allocated by the subsystems during installation.
Storage
EBS
The EBS/gp2 storage class is applied, EBS is a supported type of block storage for APIC. Note that in AWS, EBS storage is tied to an availability zone.
In case the mgmt components would have been deployed in a HA configuration, the APIC components would synchronize the data between the different instances (Cassandra, MySQL). Therefore, in this scenario having EBS storage tied to the specific availability zone would still work.
ECR
The IBM installation images are uploaded to ECR. Because the repositories are not created automatically as compared to a standard docker registry, they need to be created beforehand:
aws ecr create-repository --repository-name apic-v2018.4.1.9/analytics-client--region eu-west-1S3
S3 storage is used by the following subsystems
- API Manager
- Developer Portal
- Analytics
The backup can be configured for the API Manager and Developer Portal during installation, for these sub systems the S3 storage buckets are created beforehand.
For the analytics subsystem the S3 storage bucket needs to be created by apicup, in our case temporary permissions were given to create this storage bucket, after creation the permissions were restricted. The bucket can be created using:
apicup subsys exec tst-analytics create-s3-repo tst-analytics eu-west-1 tst-api-analytics-backup-3dfd798e https://s3.amazonaws.com <S3 Secret Key ID> <S3 Secret Access Key> backup "" "" ""
apicup subsys exec tst-analytics list-repos
Name Repo Type Bucket BasePath Region Endpoint Chunk Size Compress Server Side Encryption
tst-analytics s3 tst-api-analytics-backup-3dfd798e backup eu-west-1 https://s3.amazonaws.com 1gb true
Code language: PHP (php)CloudWatch
Log files of the containers and OS are sent to CloudWatch, FluentD is set up for this. This approach was preferred over sending the logs to remote syslog servers because it is easy to setup and Amazon offers Log Insight for analyzing the log data.
See: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Container-Insights-setup-logs.html
EmptyDir
For a couple of items (e.g. the drouter-config) the API gateway uses the EmptyDir kubernetes storage type. This implies that when a pod dies this storage is deleted. The recommended approach is to run the API Gateway in an unmanaged way. In our case the password and time zone are configured beforehand.
Installation
When preparing the installation one of the steps is to generate the output first. Values, which are not configurable through the apiconnect-up.yml file, can be changed then for:
- The scheduling of the components using affinity and node selectors;
- The CPU request amount of the API gateway;
- The additionalConfig of the API Gateway.
If no configuration of scheduling is performed, Kubernetes will schedule the components at random, components belonging to the test environment will be scheduled to the worker nodes belonging to the production environment. To solve this, the worker nodes are labeled and referred to using affinity and node selectors. The result will look like:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role/eks_cluster_role_worker_node
operator: In
values:
- tst-apic_gw
nodeSelector
nodeSelector:
node-role/eks_cluster_role_worker_node: tst-apic_mgmt
The CPU request amount cannot be 4 vCPU because the NGINX-ingress controller and FluentD agent need some CPU, after setting the CPU requested to 3 vCPU kubernetes was able to schedule the pod to the correct worker node.
API Gateway – additional configuration
Time-zone
apicup subsys install tst-gateway --out=gateway-outFor the API Gateway the extra values file contains an addition config element:
additionalConfig:
- domain: default
config: config/additional.cfgCode language: JavaScript (javascript)The additional.cfg file contains:
top; configure terminal;
%if% available "timezone"
timezone "CET-1CEST"
%endif%Code language: PHP (php)The config/additional.cfg should be added to the ./gateway-out/helm/dynamic-gateway-service folder.
Password
The secret containing the password can be created using:
kubectl create secret generic admin-credentials --from-literal=password=<the password for the TST env> --from-literal=salt=lcan --from-literal=method=sha256 -n tst-apicCode language: JavaScript (javascript)The reference to the admin-credentials should be put the values file:
vi ./gateway-out/helm/dynamic-gateway-service/values.yaml
adminUserSecret: "admin-credentials"Code language: JavaScript (javascript)Note that this way the password is used by the datapower monitor also, when for example putting in a hashed password in the additional.cfg this password will only be used by the API Gateway and will not be known by the datapower monitor. Errors due to passwords that differ between the datapower monitor and the gateway will show in the logs. (See Testing the API gateway peering later on).
Recreate the dynamic-gateway-service-1.0.56.tgz file under ./gateway-out/helm:
rm dynamic-gateway-service-1.0.56.tgz
tar czvf dynamic-gateway-service-1.0.56.tgz dynamic-gateway-serviceCode language: CSS (css)The subsystem can now be installed using:
apicup subsys install tst-gw --debug --plan-dir=./gateway-out --no-verifyVerify scheduling
To see if the pods are scheduled to the correct worker node use:
kubectl get pod -o=custom-columns=NODE:.spec.nodeName,NAME:.metadata.name -n tst-apicCode language: JavaScript (javascript)When all is configured correctly and deployed, node selectors have to be added to the kubernetes CronJobs using:
kubectl edit cronjob -n tst-apic <name>
dnsPolicy: ClusterFirst
imagePullSecrets:
- {}
nodeSelector:
node-role/eks_cluster_role_worker_node: tst-apic_mgmt
restartPolicy: OnFailure
schedulerName: default-schedulerCode language: HTML, XML (xml)Note that in AWS no imagePullSecret is needed, because this was empty in the apiconnect-up.yml, this has a wrong syntax when editing the cron job yml. So, when the node selector is added, delete the imagePullSecret in order to be able to save the changes.
For the API Manager and API Gateway extra values files are used, for the API Manager the settings can be found at: https://www.ibm.com/support/knowledgecenter/SSMNED_2018/com.ibm.apic.install.doc/tapic_install_extraValues_Kubernetes.html
Persistent volumes
Default the storage class gp2 has the reclaimPolicy: Delete, the storage class can be changed before installing, or the persistent volumes can be edited afterwards to have the reclaimPolicy: Retain. Now when the persistent volume claim is deleted, the persistent volume is kept, which is a safer option.
Testing the API gateway peering (production environment)
Checking the logs of the datapower monitor pod:
[2020-02-20T13:14:05.820Z] Checking pods matching app==dynamic-gateway-service,release==r5673b1bbde
[2020-02-20T13:14:05.836Z] Found 3 pods:
[2020-02-20T13:14:05.836Z] Pod apic/r5673b1bbde-dynamic-gateway-service-0 (Running, Ready)
[2020-02-20T13:14:05.836Z] Pod apic/r5673b1bbde-dynamic-gateway-service-1 (Running, Ready)
[2020-02-20T13:14:05.836Z] Pod apic/r5673b1bbde-dynamic-gateway-service-2 (Running, Ready)
[2020-02-20T13:14:05.836Z] Sending GatewayPeeringStatus request to r5673b1bbde-dynamic-gateway-service-0 (172.26.66.26:5550)
[2020-02-20T13:14:05.837Z] Sending GatewayPeeringStatus request to r5673b1bbde-dynamic-gateway-service-1 (172.26.65.135:5550)
[2020-02-20T13:14:05.837Z] Sending GatewayPeeringStatus request to r5673b1bbde-dynamic-gateway-service-2 (172.26.67.247:5550)
[2020-02-20T13:14:29.805Z] Gateway Peering gwd on pod r5673b1bbde-dynamic-gateway-service-1 has no stale peers
[2020-02-20T13:14:29.805Z] Gateway Peering gwd on pod r5673b1bbde-dynamic-gateway-service-2 has no stale peers
[2020-02-20T13:14:29.805Z] Gateway Peering gwd on pod r5673b1bbde-dynamic-gateway-service-0 has no stale peers
[2020-02-20T13:14:29.805Z] Gateway Peering rate-limit on pod r5673b1bbde-dynamic-gateway-service-1 has no stale peers
[2020-02-20T13:14:29.805Z] Gateway Peering rate-limit on pod r5673b1bbde-dynamic-gateway-service-2 has no stale peers
[2020-02-20T13:14:29.805Z] Gateway Peering rate-limit on pod r5673b1bbde-dynamic-gateway-service-0 has no stale peers
[2020-02-20T13:14:29.806Z] Gateway Peering subs on pod r5673b1bbde-dynamic-gateway-service-1 has no stale peers
[2020-02-20T13:14:29.806Z] Gateway Peering subs on pod r5673b1bbde-dynamic-gateway-service-2 has no stale peers
[2020-02-20T13:14:29.806Z] Gateway Peering subs on pod r5673b1bbde-dynamic-gateway-service-0 has no stale peers
[2020-02-20T13:14:29.806Z] Gateway Peering tms on pod r5673b1bbde-dynamic-gateway-service-1 has no stale peers
[2020-02-20T13:14:29.806Z] Gateway Peering tms on pod r5673b1bbde-dynamic-gateway-service-2 has no stale peers
[2020-02-20T13:14:29.806Z] Gateway Peering tms on pod r5673b1bbde-dynamic-gateway-service-0 has no stale peers
Configuration
unexpected behavior was seen:
- Unsupported protocol
- Time-out
Unsupported protocol
In our case the protocol had to be changed from SSLv3 to TLSv1.2, to see what protocol is used by the SMTP server, openssl can be used:
openssl s_client -connect smtp.<domain>:587 -starttls smtp
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES256-SHA384Code language: CSS (css)Time-out
The time-out can be increased using the apic command (note that the DNS prefix of the cloud manager is tst-api-cloud):
./apic login -u admin -p <password> -s tst-api-cloud.<domain> -r admin/default-idp-1
./apic mail-servers:list -s tst-api-cloud.<domain> -o admin --fields name
./apic mail-servers:get <smtp-server> -s tst-api-cloud.<domain> -o adminCode language: HTML, XML (xml)Edit the <mail-server-name>.yaml file, change the timeout value and set the correct password.
./apic mail-servers:update <smtp-server> smtp-server.yaml -s tst-api-cloud.<domain> -o admin
./apic mail-servers:list -s tst-api-cloud.<domain> -o admin --fields name,timeout
./apic logout --server tst-api-cloud.<domain>Code language: HTML, XML (xml)Conclusion
The most important points to address were:
- Deploying the API Gateway in an unmanaged way plus having custom configuration and a password different from the default one
- Taking advantage of the different availability zones for each API gateway in production
- Kubernetes to schedule the different components to the correct worker nodes. For accomplishing this, values of the helm charts need to be adjusted. Direct install using the apiconnect-up.yml configuration does not offer this.
After these points were figured out, it was straightforward to complete the installation.
Jaco Wisse
IT Architect @ Integration Designers
Integration Designers focusses on IBM products in the integration domain.
IBM Integration Specialists
Enabling Digital Transformations.
Recent news
Let's get in touch...
 Find us here
Find us here
Veldkant 33B
2550 Kontich
Belgium
Pedro de Medinalaan 81
1086XP Amsterdam
The Netherlands
![]() © 2019 Integration Designers - Privacy policy - Part of Cronos Group & integr8 consulting
© 2019 Integration Designers - Privacy policy - Part of Cronos Group & integr8 consulting